Clustering is a technique used in unsupervised machine learning in which a machine is given a dataset and tasked with finding groups, or clusters, within the data. There are two main forms of clustering: flat clustering and hierarchical clustering. In flat clustering, we specify the number of clusters that the machine should find. Hierarchical clustering allows the machine to determine the number of clusters and the subgroups within them.
For the exercises, we will use a dataset that I developed based on publicly available reports and data on forests and forest wildlife.
Animal_data_2024_large
import pandas as pd
import numpy as np
import math
# Load the dataset
animals = pd.read_csv(
'Animal_data_2024_large.csv',
sep=';')
print(animals.info())
for col in animals.select_dtypes(include=['float64']).columns:
animals[col] = animals[col].fillna(0).astype('int64')
K-means is a simple and widely used clustering algorithm whose goal is to partition a dataset into k distinct clusters.The algorithm begins by randomly initializing k cluster centroids and then iteratively assigning each data point to the nearest centroid. It subsequently recalculates the centroids based on the mean of the data points assigned to each cluster. This process continues until convergence is reached, meaning that the centroids no longer change significantly, or until the maximum number of iterations has been reached.
To apply the K-means algorithm we can use scikit-learn, that provides a straightforward implementation of the K-means algorithm, making it easy to apply in real-world examples.
Libriaries we will use:
from sklearn.model_selection import cross_validate,train_test_split
from sklearn import preprocessing, svm, neighbors
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.cluster import KMeans
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
Data Preparation and Standardization
X = animals.drop(['Hunting_Dist_ID','Hunting_Dist_name'], axis=1)
# Conversion
X = X.values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print(X_scaled)
K-Means with k number of clusters and pre-visualization
# K-MEANS
inertia = []
K_range = range(1, 10)
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
kmeans.fit(X_scaled)
inertia.append(kmeans.inertia_)
plt.plot(K_range, inertia, marker='o')
plt.xlabel("Number of clusters")
plt.ylabel("Inertia")
plt.show()
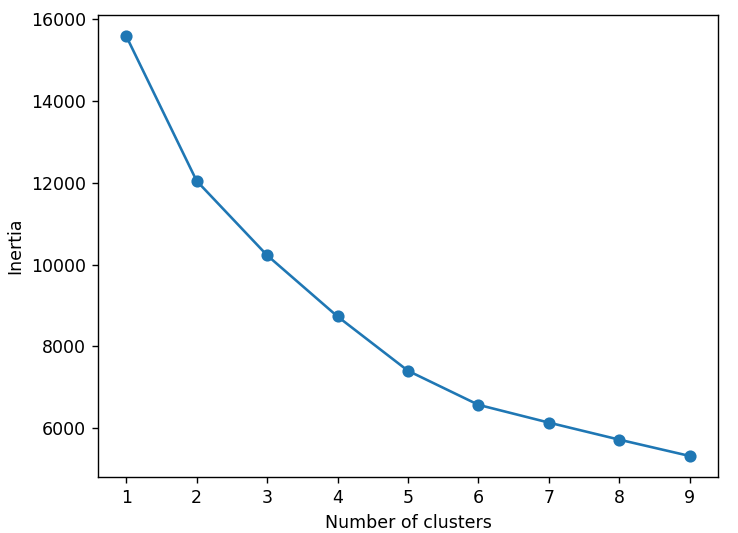
K-Means with a defined number of clusters of 3
# Final K-Means
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
clusters = kmeans.fit_predict(X_scaled)
animals["cluster_kmeans"] = clusters
print(animals["cluster_kmeans"].value_counts())
output: cluster_kmeans
0 1956
1 629
2 13
Name: count, dtype: int64
Visualization (2D)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_2d = pca.fit_transform(X_scaled)
plt.scatter(X_2d[:,0], X_2d[:,1], c=clusters)
plt.title("K-Means clusters")
plt.show()
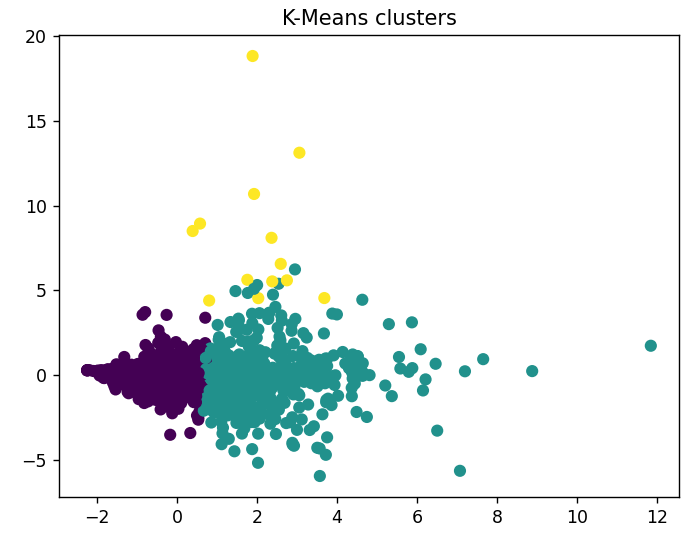
Mean Shift is another clustering algorithm that does not require the number of clusters to be specified in advance. Instead, it iteratively moves each data point toward the mode of its local neighborhood until convergence is reached. The mode represents the region with the highest density of data points within a given radius. The resulting clusters are defined by these points of convergence.
Compared to K-means, Mean Shift is more flexible because it automatically determines the number of clusters based on the underlying distribution of the data. It can handle clusters with irregular shapes and is less sensitive to the initial placement of data points.
# K-SHIFT
from sklearn.cluster import MeanShift
ms = MeanShift()
clusters_ms = ms.fit_predict(X_scaled)
animals["cluster_ms"] = clusters_ms
print(animals["cluster_ms"].value_counts())
plt.scatter(X_2d[:,0], X_2d[:,1], c=clusters_ms)
plt.title("Mean Shift clusters")
plt.show()
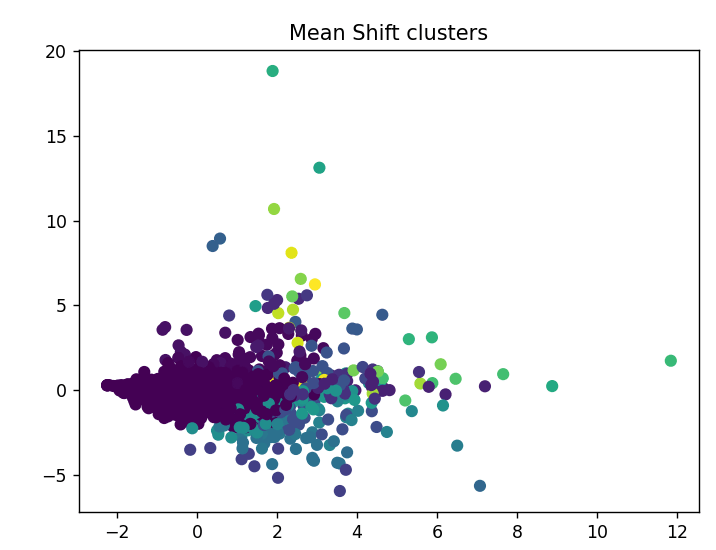
In practice, clustering algorithms can be used in semi-supervised machine learning. After clustering, the resulting groups can be incorporated into a supervised learning workflow, where the clusters serve as labels for classification tasks using other algorithms, such as Support Vector Machines (SVMs).
