Before we move further with deeper python and machine learning, let’s go back for a moment, what we used pandas and numpy for. Let AI refresh our memory.
Hello AI!, let's go through the pandas and numpy library in Python today. Can you show me some useful examples ?
Installation

Import into current File:
import pandas as pd
import numpy as np
NumPy
Basics
import numpy as np
a = np.array([1,2,3,4])
print(a)
#[1 2 3 4]
b = np.array([[1,2],[3,4]])
print(b)
# [[1 2]
# [3 4]]
zeros = np.zeros((2,2))
print(zeros)
# [[0. 0.]
# [0. 0.]]
ones = np.ones((3,2))
print(ones)
# [[1. 1.]
# [1. 1.]
# [1. 1.]]
arange = np.arange(0,5,1)
print(arange)
arange = np.arange(0,10,2)
print(arange)
arange = np.arange(1,15,3)
print(arange)
#1: [0 1 2 3 4]
#2: [0 2 4 6 8]
#3: [ 1 4 7 10 13]
linspace = np.linspace(0,1,6)
print(linspace)
linspace = np.linspace(0,10,6)
print(linspace)
# [0. 0.2 0.4 0.6 0.8 1. ]
# [ 0. 2. 4. 6. 8. 10.]
# Ops on Arrays
x = np.array([1,2,3])
y = np.array([4,5,6])
print(x+y)
print(x*y)
# [5 7 9]
# [ 4 10 18]
a = np.array([[1,2],[3,4]])
b = np.array([[11,12],[13,14]])
print(np.dot(a,b))
# [[37 40]
# [85 92]]
# [[1*11+2*13, 1*12+2*14],[3*11+4*13, 3*12+4*14]]
sqrt_array = np.sqrt([1, 4, 9, 16])
print(sqrt_array)
#[1. 2. 3. 4.]
angles = np.array([0, np.pi/2, np.pi])
sin_array = np.sin(angles)
print(sin_array)
#[0.0000000e+00 1.0000000e+00 1.2246468e-16]
log_array = np.log([1, np.e, np.e**2])
print(log_array)
#[0. 1. 2.]
#indexing
a = np.array([10, 20, 30, 40, 50])
print(a[1]) # 20
#slicing
b = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(b[1:, :2])
# will return a submatrix: second row, first two columns
#stats
data = np.array([1, 2, 3, 4, 5])
print(np.mean(data)) #3
print(np.median(data)) #3
print(np.std(data)) #1.4142135623730951
#reshape
a = np.arange(1, 13)
b = a.reshape((3, 4))
print(b)
#flat
flat = b.flatten()
print(flat)
Pandas
# DataFrames
data = {
"age": [5, 12, 4, 18, 10],
"color": ["brown", "cappucino", "white", "tri-color", "black"],
"weight": [9, 112, 156, 6.5, 1.7]
}
animals = pd.DataFrame(data, index=["dog", "deer",
"cow", "cat",
"raven"])
print(animals)
# age color weight
# dog 5 brown 9.0
# deer 12 cappucino 112.0
# cow 4 white 156.0
# cat 18 tri-color 6.5
# raven 10 black 1.7
#DataFrames from dicts
data = [
{'Name': 'Alice', 'Age': 25, 'City': 'New York'},
{'Name': 'Bob', 'Age': 30, 'City': 'San Francisco'},
{'Name': 'Charlie', 'Age': 35, 'City': 'Los Angeles'}
]
df = pd.DataFrame(data)
print(df)
# Name Age City
# 0 Alice 25 New York
# 1 Bob 30 San Francisco
# 2 Charlie 35 Los Angeles
#Series
s = pd.Series([1, 2, 3, 4, 5],
name="Numbers")
print(s)
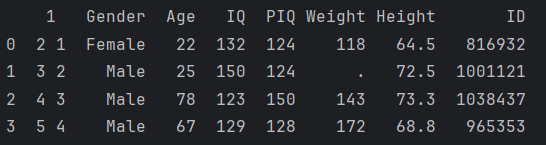
df = pd.read_csv('MW.csv')
print(df[:4])
print(df.info())
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 40 entries, 0 to 39
# Data columns (total 8 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 1 40 non-null object
# 1 Gender 40 non-null object
# 2 Age 40 non-null int64
# 3 IQ 40 non-null int64
# 4 PIQ 40 non-null int64
# 5 Weight 40 non-null object
# 6 Height 40 non-null object
# 7 ID 40 non-null int64
# dtypes: int64(4), object(4)
# memory usage: 2.6+ KB
print(df.describe())

#selected3 columns, first 3 rows
selected_data = df[['Gender', 'Age', "ID"]].iloc[:3]
print(selected_data)
Modifying data
#Adding a new column
df['Salary'] = [50000, 60000, 70000]
print(df)
#Modify an existing column:
df['Age'] = df['Age'] + 1
print(df)
#Deleting a column:
df = df.drop(columns=['Salary'])
print(df)
Data group and merge
#Grouping data and calculating aggregates:
grouped = df.groupby('Age').mean()
print(grouped)
#merge DataFrame:
df1 = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
})
df2 = pd.DataFrame({
'Name': ['Alice', 'Bob', 'David'],
'Salary': [50000, 60000, 70000]
})
merged = pd.merge(df1, df2, on='Name', how='inner')
print(merged)
#Saving data to a CSV file:
df.to_csv('output.csv', index=False)
#Saving data to Excel file:
df.to_excel('output.xlsx', index=False)
Operations on missing data
#Checking for missing values:
print(df.isnull().sum())
#Deleting rows with missing values:
df = df.dropna()
print(df)
#Filling in missing values:
df['Age'] = df['Age'].fillna(df['Age'].mean())
print(df)
